Nel caso di progetti manutenuti e che vengono installati presso vari clienti capita spesso di installare una versione che nel giro di poco tempo diventa obsoleta in quanto il ramo di sviluppo evolve rapidamente.
Ci troviamo quindi nella situazione di avere versioni differenti installate presso i clienti ( non su un nostro server ma on premise) ai quali dobbiamo fare alternativamente:
- minor fix
- aggiornamenti all’ultima versione
Abbiamo quindi un progetto che evolve e potenzialmente molto differente rispetto alla versione installata presso i clienti.
Si presentano quindi queste esigenze:
- Tracciare la versione esatta installata dal cliente
- Lavorare sulla versione installata presso il client per effettuare fix minori e committarle
- Aggiornare la versione installata presso il cliente all’ultima versione
- Poter sviluppare un progetto all’interno di un ramo di sviluppo differente da quello “master” e poi portare sul progetto “master” alcune modifiche
Immagino che possiate avere esigenze simili .
Voi come le risolvete ? io qui riporto quello che stiamo facendo attualmente:
Punto 1: effettuiamo un backup all’interno di teamworks ogni volta che rilasciamo una versione presso un cliente. In futuro contiamo di aggiungere il numero di checkin nella pagina di login ( feature però presente solo in InDe 21 (https://doc.instantdeveloper.com/?ARTID=BF65D91F-4AF2-48D6-8C4F-DF819A068330&LANG=it)
Effettuare un backup però è una operazione manuale che può introdurre errori o dimenticanze. La tecnica del numero checkin è probabilmente più affidabile
Punto 2:
questa è una operatività (per quello che ne so) praticamente impossibile se vogliamo effettuare il fix e ed effettuare il check-in di quel fix su quella versione in quanto non esistono rami differenti da quello di lavoro “master”. Per ora non resta che:
- effettuare il download dell’idp (dai checkin o dai backup)
- effettuare la modifica
- rilasciare presso il cliente
- tenere l’idp modificato fuori teamworks su onedrive, google drive o, in generale, su hard disk
Il problema deriva dal fatto che non è possibile effettaure un progetto derivato partendo da un checkin passato. Nell’ipotesi di creare un ramo derivato dal progetto all’ultima versione quest’ultimo avrà un GUID differente che non permetterà di usarlo per aggiornare via idp l’installazione presso il cliente.
Punto 3:
l’operazione è tutto sommato semplice usando idmanager dalla versione attuale ed è l’operatività standard.
Punto 4:
Questa operatività non è possibile con gli strumenti attuali e la stiamo simulando lavorando su progetti copia e poi portando con drag & drop le modifiche. Questo generà però molte volte problemi e non è un metodo sicuro
Mi piacerebbe capire come risolvete problemi simili e se avete soluzioni più efficaci
2 Mi Piace
In tutta sincerità, ci abbiamo provato ma abbiamo rinunciato.
L’equilibrio tra le nostre esigenze e quello che costa (in termini di tempo e grattacapi) gestire versioni differenti su TW è decisamente a sfavore. La mia personale conclusione, opinabile, è che TW è pensato per gestire il lavoro contemporaneo sullo stesso progetto, ma non per gestire versioni diverse dello stesso progetto in produzione. Benvenute eventuali smentite 
Per ora, abbiamo un’unica versione delle applicazioni in produzione, gestendo logiche differenti tramite videate differenti e setup che modificano il flusso di alcuni ambiti.
1 Mi Piace
Grazie @martino.vedana di questo articolo, è proprio questo lo spirito di questa Community.
Mi prendo del tempo per parlarne con un mio collega e poi posto anche le nostre considerazioni sull’argomento.
2 Mi Piace
Teamworks rispetto a un VCS tradizionale ha di certo moltissimi vantaggi.
Io trovo di estremo valore la possibilità di fare snapshot per tornare a un punto nel passato (“mi ricordo che a febbraio questa cosa era diversa…”), di certo il “viaggio nel tempo” è reso difficile dai componenti: se i componenti usati sono correttamente versionati allora si riesce davvero a tornare a un punto qualsiasi e ad esempio riuscire a fare un fix a una versione vecchia.
Bisogna essere però puntuali nella creazione di branch: ogni volta che si rilascia si dovrebbe fare un branch, ma siccome si può fare anche a meno non nascondo che spesso non lo facciamo.
Se le app avessero la versione come ce l’hanno i copmponenti forse la cosa sarebbe più semplice.
In ogni caso i 4 punti che citi sono fondamentali per tutti credo.
Noi per il punto 1 abbiamo fatto un componente che fa “call home” e quindi come una sorta di anaytics manda ad una nostra app di controllo di tutte le installazioni alcuni dati di utilizzo, tra cui la versione installata, che è una proprietà che gestiamo nell’applicazione in una nostra classe di controllo della versione.
Questo lo facciamo siccome non usiamo ID Manager ma ci siamo fatti (ci stiamo facendo) un sistema custom di deployment che ho descritto in un’altra risposta.
quindi per la (1) ti direi che noi quando facciamo una build impostiamo una stringa in un parametro prima di compilare e quella diventa la versione, la app installata poi ci rimanda la stringa chiamando un webserver della nostra app di controllo dell’installato (che oltre al nome versione ci dà anche info come “totale accessi nel mese” e “ultimo accesso”,e ci permette di spegnere la applicazione - però questa parte è ancora in sviluppo ed embrionale, per quanto funzionante).
Sul punto (4) devo dire che master e branch + Drag&Drop funziona bene, l’unica cosa che è scomoda è che facendo Drag&Drop ad esempio di un metodo da master a una branch, se il fix coinvolge una costante il metodo (giustamente, per come ragiona Inde) non se la porta dietro e quindi il fix non si propaga. Sarebbe comodo (e ho fatto un suggerimento in Together in questa direzione) che shift-Drag propagasse anche le costanti.
Per il resto concordo che i 4 punti sono chiave e se Foundation evolvesse anche in quella direzione sarebbe super. In fondo io vedo Inde come “R&D preconfezionata”: se devo farmi io il sistema di deployment non va bene.
Ciao!
1 Mi Piace
Ciao,
premetto che noi abbiamo sviluppato i nostri progetti a componenti, abbiamo un solo progetto core che, tramite la funzione createformfromlibrary istanzia le dll dei vari componenti.
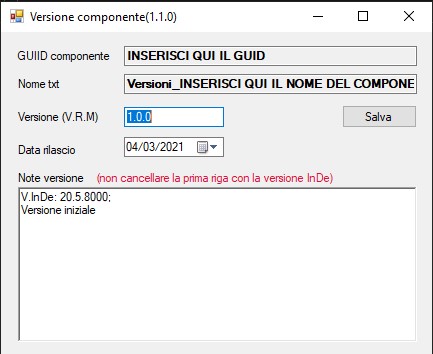
Quando installiamo presso i clienti, oltre alle dll, installiamo anche un file di testo(creato da un programmino in dotnet) in cui ci sono il guid, la versione, la data di rilascio, la descrizione del componente e la versione di compilazione di InDe, tutto questo viene poi letto ogni giorno al primo login e passato tramite webservice, sul nostro DB centrale, in questo modo, per ogni cliente, sappiamo che componenti e con quali caratteristiche ha installati, rendendo più facile le procedure di aggiornamento e manutenzione.
Per ora è ancora tutto un po’ manuale, ma lo stiamo affinando.
Di seguito vi metto l’immegine del programma in dotnet e il contenuto del txt.
contenuto file .txt
1.0.0
04/03/2021
INSERISCI QUI IL GUID
V.InDe: 20.5.8000;
Versione iniziale
Cercando materiale sul tema TeamWorks e gestione di versioni e progetti derivati ho trovato questa discussione.
Riassumendo ho trovato questi problemi:
- creare progetto derivato a partire da un checkin.
- effettuare modifiche sul progetto derivato.
- mantenere storico della modifica sul progetto derivato.
- unire le modifiche al progetto principale.
- installare il progetto derivato con IDManager su una precedente installazione di un altro ramo.
- gestire il flusso di codice tra le varie versioni.
@martino.vedana ho capito bene? Mi piacerebbe affrontare tutto in un unico articolone organico.
@r.bianco potresti aiutarmi a capire il bilancio sfavorevole di cui avevi parlato?
Scusate se ho riesumato una cosa vecchia, ma mi sembra troppo interessate per lasciarla lì senza ulteriori sviluppi.
3 Mi Piace
Ecco questi sono forse i punti più critici secondo me
Premesso che non ho capito come si fa (e non ci ho mai provato), ma il fatto di poter prendere lock in 2 programmatori sullo stesso oggetto e poi dover risolvere le collisioni, testare che funzioni etc ci tiene un po’ alla lontana dal lavorare con branch.
Sono andato a rileggermi i post nel forum in cui discutevo dell’argomento, un decennio fa 
In sostanza, il mio problema ad usare i branch è dovuto alla conseguente gestione manuale che poi ne deriva.
Un primo esempio è quello in cui abbiamo una versione master che va in produzione, e un branch della stessa su cui proseguiamo lo sviluppo. In questa situazione TW aiuta gli sviluppatori a non sovrapporre modifiche, grazie ai lock, ma perdiamo la funzionalità di Recupera ultima versione nella versione da pubblicare in produzione. In questo caso siamo costretti a lavorare sempre con Mostra differenze, dovendo gestire il merge a mano tramite drag&drop e risolvendo da noi eventuali conflitti.
Nel secondo caso, ogni sviluppatore lavora su un branch separato. In questo caso non abbiamo un controllo sulla sovrapposizione di modifiche da parte di TW, e dobbiamo gestire a mano il merge sia per la versione in sviluppo che per quella in produzione.
Detto in altri termini, un branch è una copia del progetto che mantiene i GUID degli oggetti, messo a sua volta su TW, e questo permette il drag&drop tra le due. Nulla di più. Non c’è alcuna funzionalità di versionamento e allineamento, è tutto demandato all’utente.
Ora abbiamo una copia del progetto, anch’essa collegata a TW, in cui prendiamo solo le modifiche che andranno in produzione, ed è questa che poi verrà pubblicata in produzione. Otteniamo lo stesso risultato, e possiamo usare Recupera ultima versione.
Non trovo vantaggi nell’usare un branch.
Mi auguro di aver risposto, l’argomento ci interessa molto 
Mi intrometto nella discussione.
Quoto @r.bianco.
Io ad ogni rilascio cristallizzo il progetto che è finito il produzione salvandone una copia con TW disabilitato. Questo mi consente di usare TW per la collaborazione con in colleghi durante lo sviluppo.
Se devo rilasciare patch, prendo il progetto salvato durante l’ultimo rilascio, faccio la modifica lì sopra e poi riporto le modifiche sul progetto di sviluppo.
Ho sempre trovato il sistema di drag&drop non adatto a fare il merge di versioni diverse. E’ sempre meglio che rifare le cose 2 volte, ma è poco comodo quando per esempio si devono portare da un progetto all’altro solo alcune parti di un metodo oppure fare un merge più complesso. Ad esempio non si può fare il drag&drop nella finestra delle differenze, ma tocca chiuderla e poi andare a lavorare sugli alberi di progetto. Se si hanno 50 oggetti di cui solo 30 devono essere allineati, è molto scomodo.
Mi rendo ovviamente conto che INDE non lavora su file di testo, e non si possono usare VCS come Git. Nel mio caso questa è sempre stata una scomodità calcolata, che ritengo accettabile visti i vantaggi che INDE offre in altri campi.
Devo anche ammettere che ho sempre usato INDE su progetti con un ciclo di sviluppo/rilascio lineare, dove tutti i programmatori lavorano sullo stesso branch e i rilasci sono (più o meno) coordinati.
1 Mi Piace
Si, questo è quello di cui ci sarebbe bisogno ma aggiungo un aspetto aspetto:
il cambio GUID del progetto che ora è un componente esterno dovrebbe essere di serie poichè e’ molto utile ( anche se pericoloso)
Ci sono poi questioni legate all’app web di teamworks ma rientra nel presentation layer e nonnnelle funzionalità dello strumento