Sul web ho cercato spiegazioni semplici sugli “embeddings”.
Ho riportato brevemente quel che ho trovato di semplice in vari articoli.
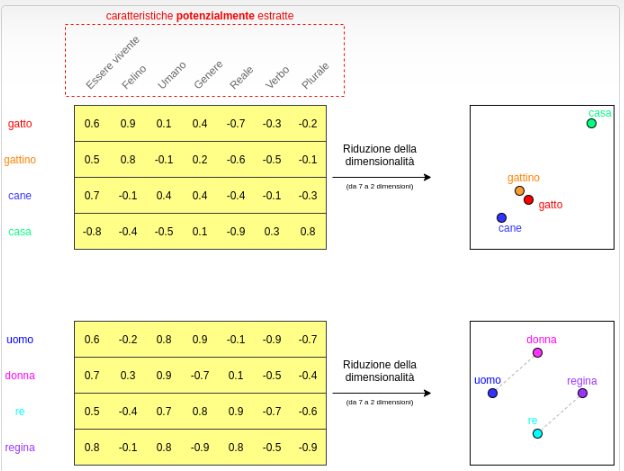
I vettori di embedding di parole sono ottenuti da algoritmi di apprendimento automatico non supervisionati che ricevono una grande quantità di testo grezzo come unico input . L’idea alla base di questi algoritmi è tanto semplice quanto geniale: imparare a incorporare un certo termine usando le parole vicine nel testo di input come dati.
Questo approccio si basa sulla cosiddetta ipotesi distributiva , formulata nel 1954 dal linguista americano Zelling S. Harris, secondo la quale le parole che ricorrono in contesti simili tendono ad avere significati simili.
L’idea è cioè che il contesto di una parola, che ne può determinare il significato, sono le parole che occorrono nelle «vicinanze» di essa in un testo (per esempio fra le 5 parole che la precedono e le 5 che la seguono).
Esempio con 2 parole prima e dopo:
"Quel ramo del lago di Como, che volge a mezzogiorno, tra monti tutto a seni e a golfi
"Quel ramo del lago di Como, che volge a mezzogiorno, tra due tutto a seni e a golfi
"Quel ramo del lago di Como, che volge a mezzogiorno, tra due a seni e a golfi
«Una parola è caratterizzata dalla compagnia in cui si trova.» John Rupert Firth.
Algebra della semantica:
p(v(“bigger”) - v(“big”) + v(“cold”)) = “colder”
p(v(“Paris”) - v(“France”) + v(“Italy”)) = “Rome”
p(v(“sushi”) - v(“Japan”) + v(“Germany”)) = “bratwurst”
p(v(“Windows”) - v(“Microsoft”) + v(“Google”)) = “Android”
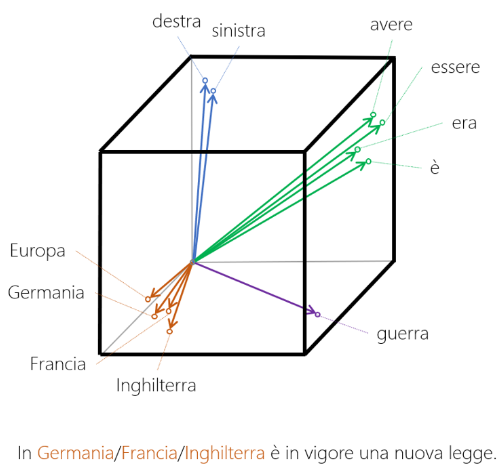
Germania, Francia e Inghilterra hanno, in questo caso, lo stesso contesto, però esisteranno casi in cui i contesti sono simili ma non identici, per esempio: La Germania segna un gol alla Francia, l’Inghilterra segna un gol su azione e uno su rigore alla Germania.